Recent advancements in multimodal large language models (MLLM) have revolutionized various fields, leveraging the transformative capabilities of large-scale language models …
read more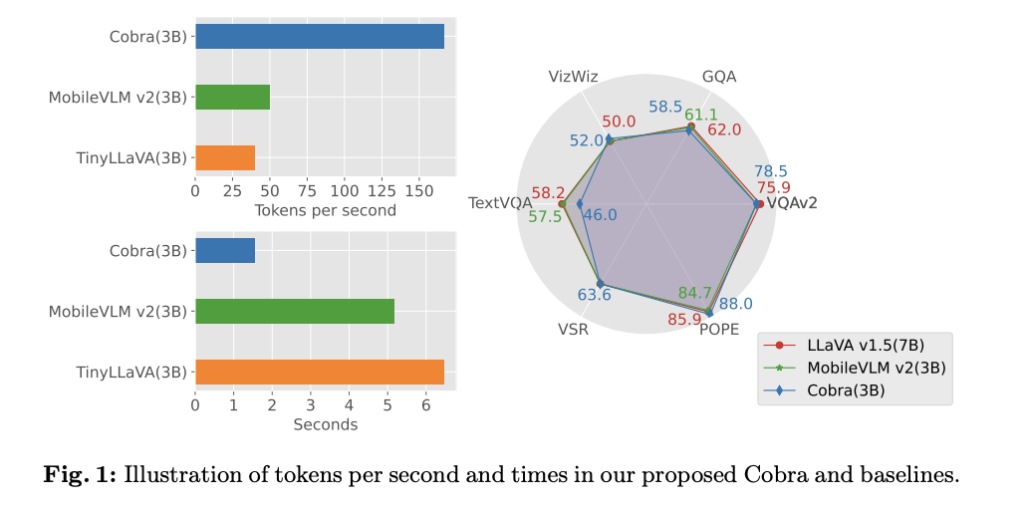
Cobra for Multimodal Language Learning: Efficient Multimodal Large Language Models (MLLM) with Linear Computational Complexity
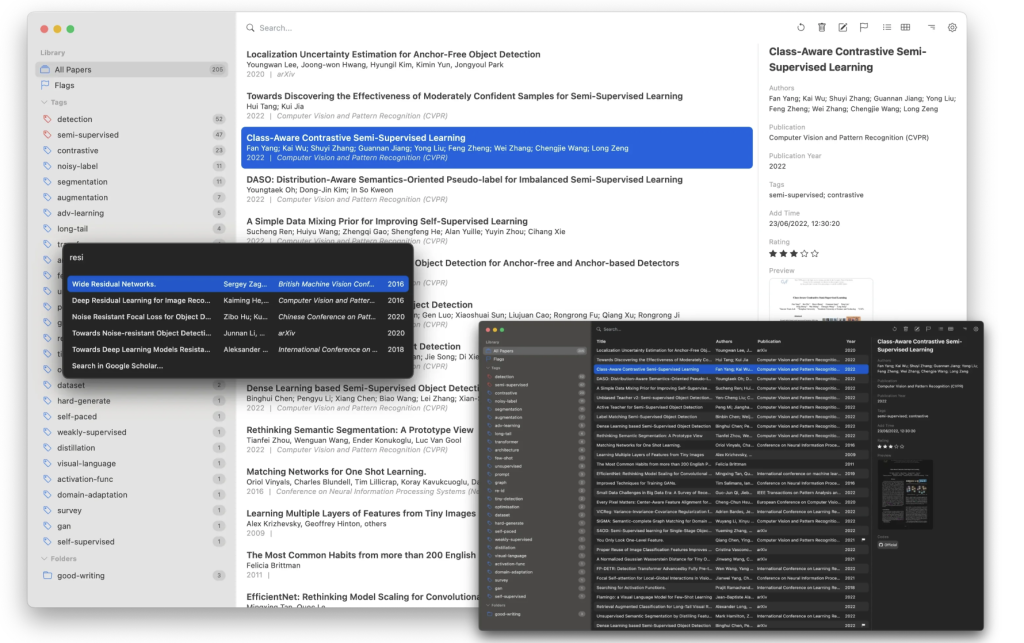
Paperlib: An Open-Source AI Research Paper Management Tool
In academic research, particularly in computer vision, keeping track of conference papers can be a real challenge. Unlike journal articles, …
read more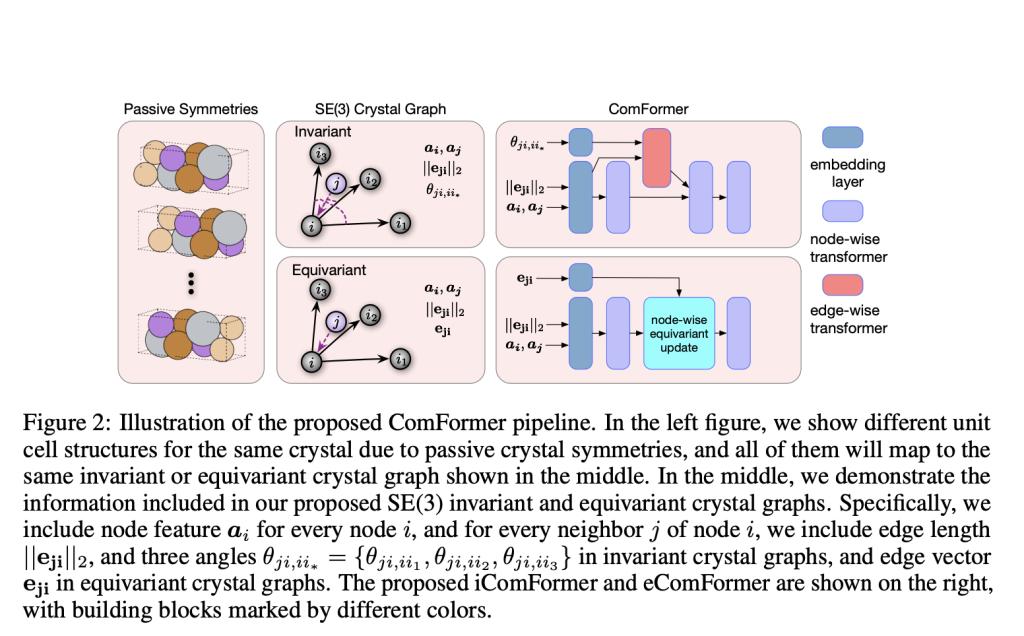
Researchers at Texas A&M University Introduces ComFormer: A Novel Machine Learning Approach for Crystal Material Property Prediction
The search for rapid discovery and materials characterization with tailored properties has recently intensified. One of the central aspects of …
read more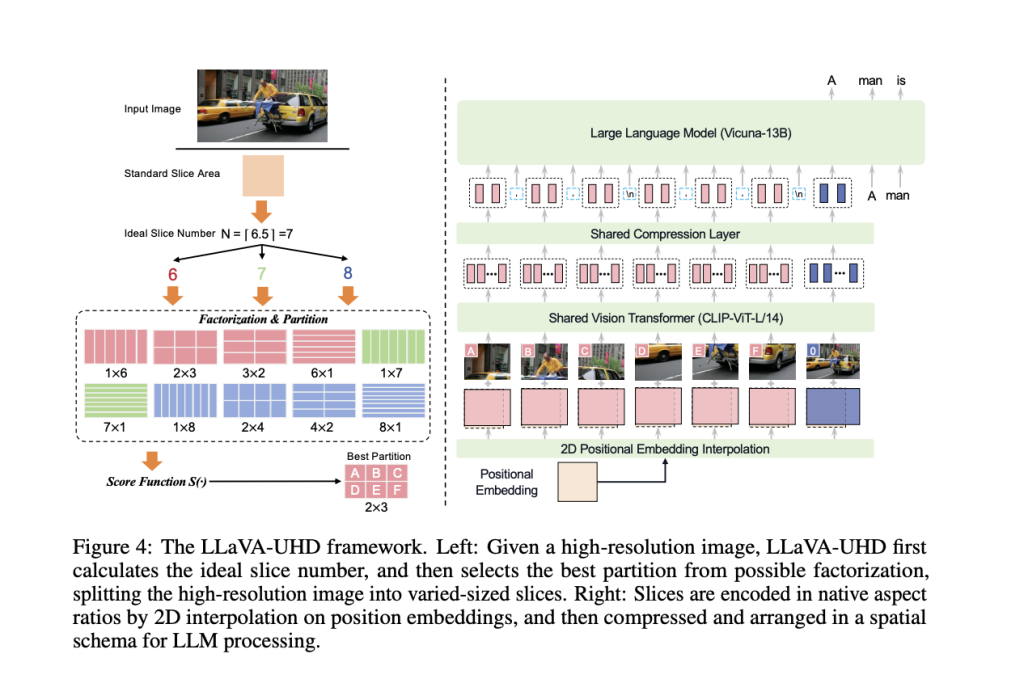
Seeing it All: LLaVA-UHD Perceives High-Resolution Images at Any Aspect Ratio
Large language models like GPT-4 are incredibly powerful, but they sometimes struggle with basic tasks involving visual perception – like …
read more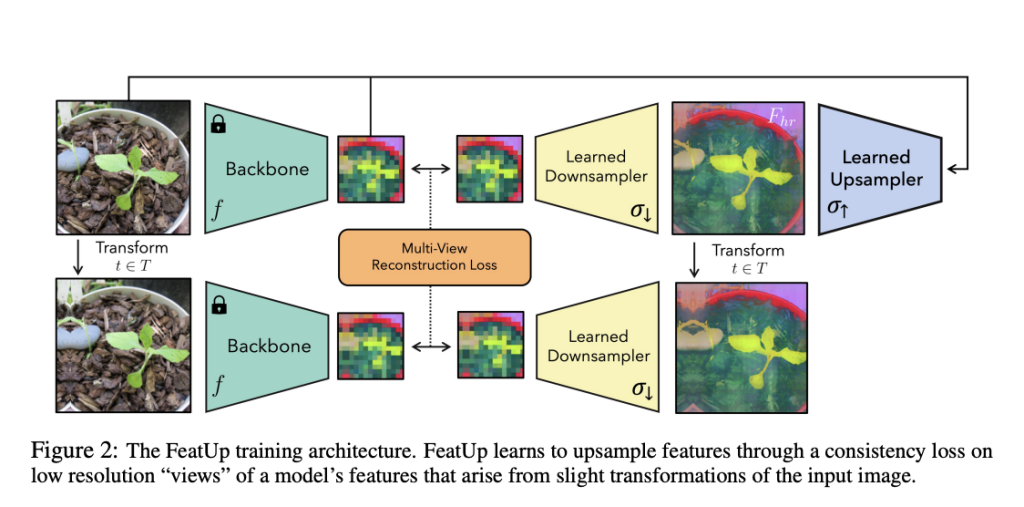
FeatUp: A Machine Learning Algorithm that Upgrades the Resolution of Deep Neural Networks for Improved Performance in Computer Vision Tasks
Deep features are pivotal in computer vision studies, unlocking image semantics and empowering researchers to tackle various tasks, even in …
read more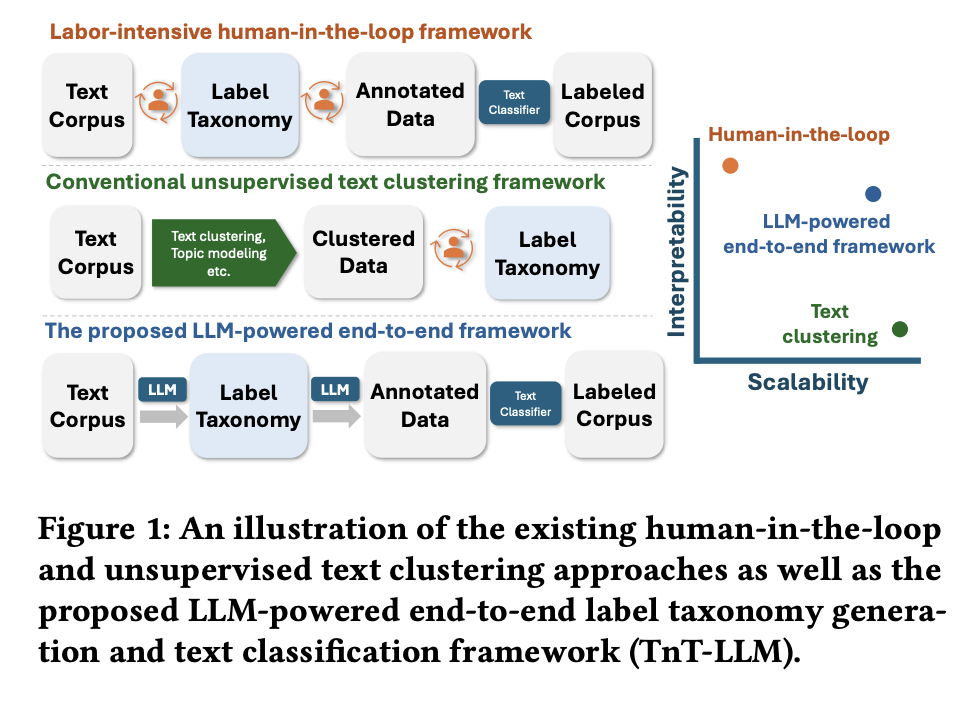
Tnt-LLM: A Novel Machine Learning Framework that Combines the Interpretability of Manual Approaches with the Scale of Automatic Text Clustering and Topic Modeling
The term “text mining” refers to discovering new patterns and insights in massive amounts of textual data. Generating a taxonomy—a …
read more
HuggingFace Introduces Quanto: A Python Quantization Toolkit to Reduce the Computational and Memory Costs of Evaluating Deep Learning Models
HuggingFace Researchers introduce Quanto to address the challenge of optimizing deep learning models for deployment on resource-constrained devices, such as …
read more
Stability AI founder and CEO Emad Mostaque resigns
Join Gen AI enterprise leaders in Boston on March 27 for an exclusive night of networking, insights, and conversations surrounding …
read more
The metrics you can’t afford to ignore: What the best CEOs know
Join Gen AI enterprise leaders in Boston on March 27 for an exclusive night of networking, insights, and conversations surrounding …
read more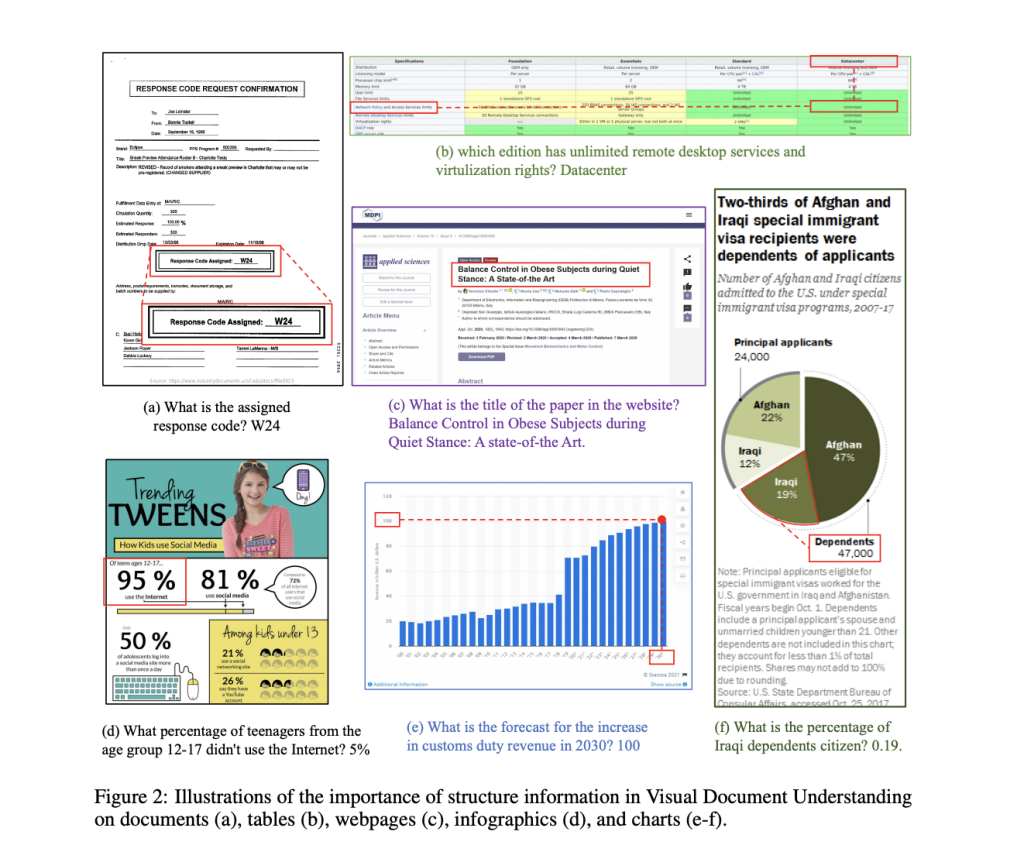
Researchers from Alibaba and the Renmin University of China Present mPLUG-DocOwl 1.5: Unified Structure Learning for OCR-free Document Understanding
Harnessing the strong language understanding and generation potential of Large Language Models (LLMs), Multimodal Large Language Models (MLLMs) have been …
read more
Categories
Copyright © 2023 Every Intel. All Right Reserved.