Mixture-of-experts (MoE) architectures use sparse activation to initial the scaling of model sizes while preserving high training and inference efficiency. …
read more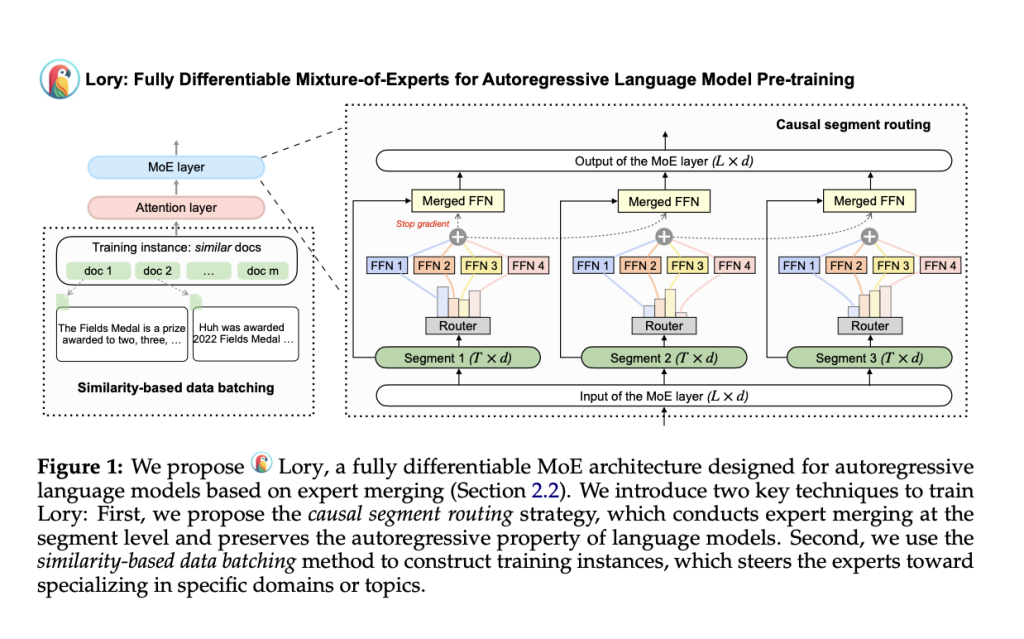
Researchers from Princeton and Meta AI Introduce ‘Lory’: A Fully-Differentiable MoE Model Designed for Autoregressive Language Model Pre-Training

Ethereum Transaction Fees Slide Nearly 94% Over the Past 68 Days
Similar to Bitcoin’s onchain fees, the cost of transacting on the Ethereum network has recently seen a significant decline. Over …
read more
Binance Launchpool Introduces Omni Network (OMNI) Tokens
Binance Launchpool brings Omni Network (OMNI) Tokens Binance has announced the introduction of Omni Network …
read more
THRONE: Advancing the Evaluation of Hallucinations in Vision-Language Models
Understanding and mitigating hallucinations in vision-language models (VLVMs) is an emerging field of research that addresses the generation of coherent …
read more
Safe Marine Navigation Using Vision AI: Enhancing Maritime Safety and Efficiency
Maritime transportation has always been pivotal for global trade and travel, but navigating the vast and often unpredictable waters presents …
read more
KnowHalu: A Novel AI Approach for Detecting Hallucinations in Text Generated by Large Language Models (LLMs)
The power of LLMs to generate coherent and contextually appropriate text is impressive and valuable. However, these models sometimes produce …
read more
Top AI Tools Enhancing Fraud Detection and Financial Forecasting
Discover the best AI Fraud Prevention Tools and Software for detecting payment fraud, identifying identity theft, preventing insurance fraud, addressing …
read more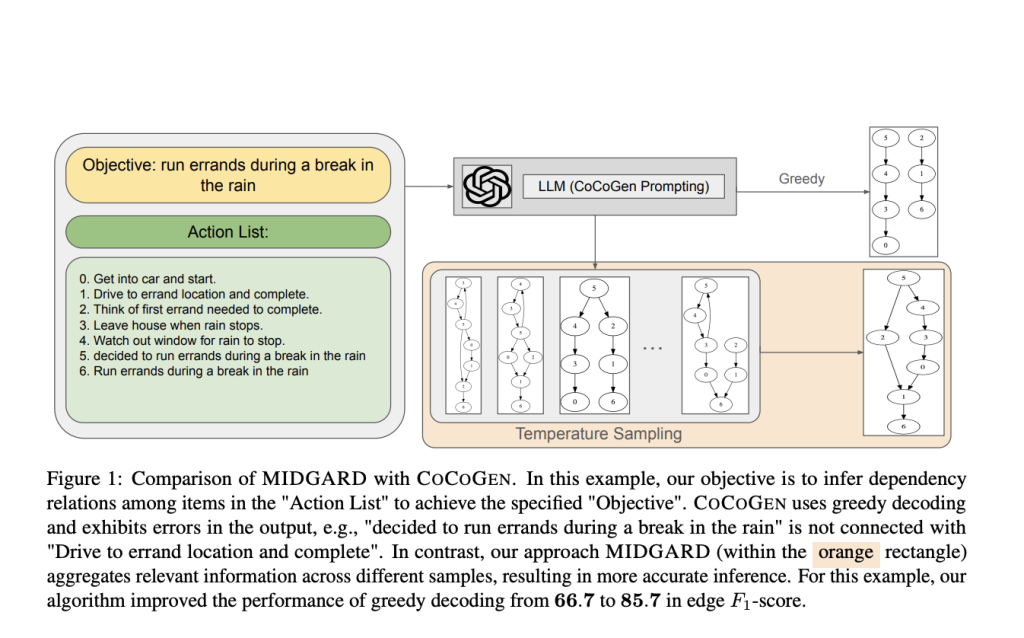
This AI Paper by the University of Michigan Introduces MIDGARD: Advancing AI Reasoning with Minimum Description Length
Structured commonsense reasoning in natural language processing involves automated generating and manipulating reasoning graphs from textual inputs. This domain focuses …
read more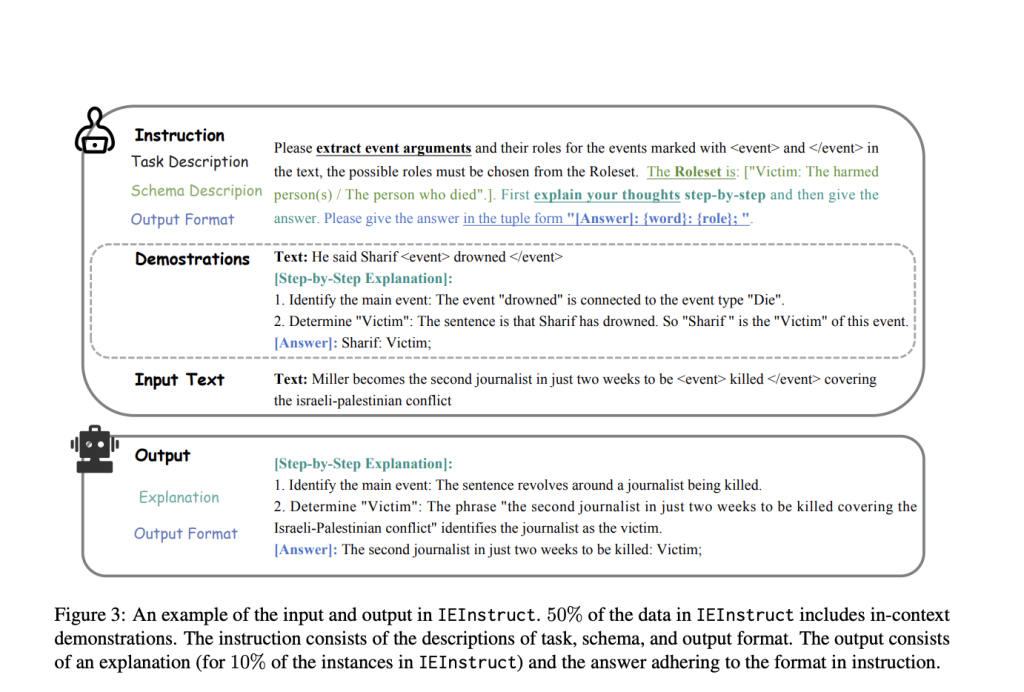
Tsinghua University Researchers Propose ADELIE: Enhancing Information Extraction with Aligned Large Language Models Around Human-Centric Tasks
Information extraction (IE) is a pivotal area of artificial intelligence that transforms unstructured text into structured, actionable data. Despite their …
read more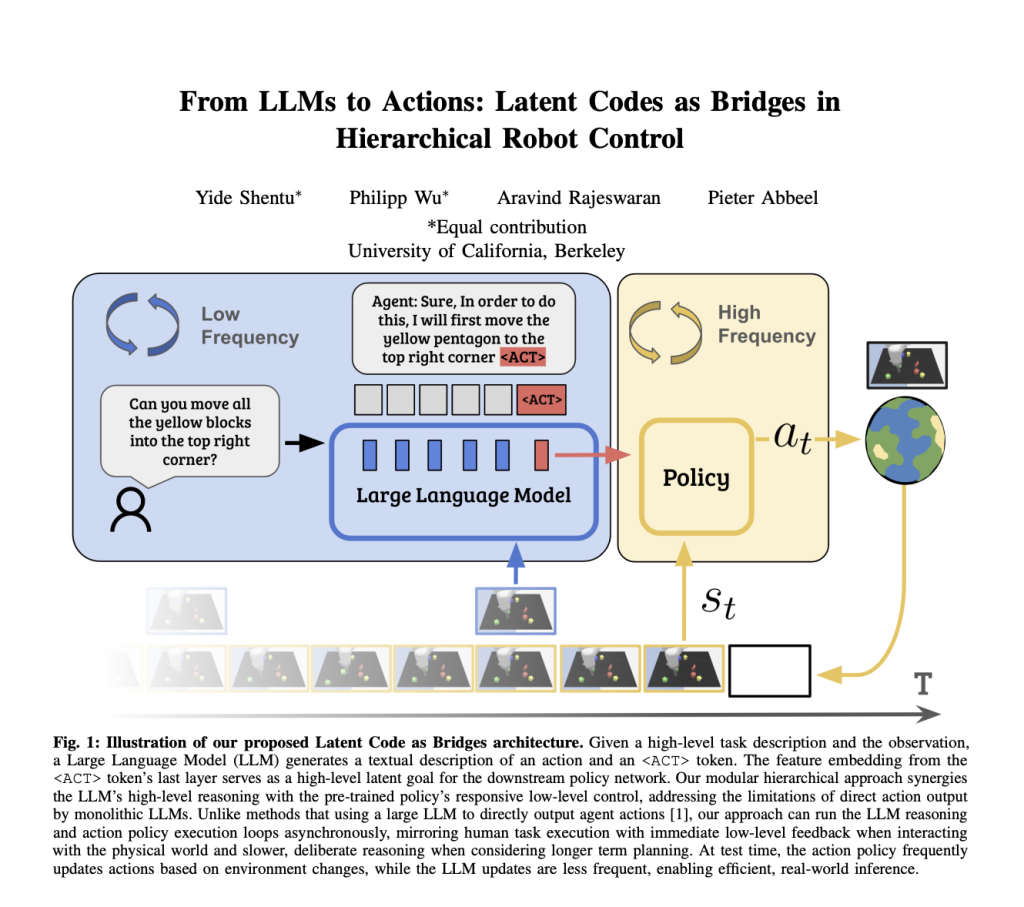
UC Berkeley Researchers Introduce Learnable Latent Codes as Bridges (LCB): A Novel AI Approach that Combines the Abstract Reasoning Capabilities of Large Language Models with Low-Level Action Policies
The robotics field has historically vacillated between two primary architectural paradigms: modular hierarchical policies and end-to-end policies. Modular hierarchies employ …
read more
Categories
Copyright © 2023 Every Intel. All Right Reserved.